 Models: Speculative, ascribed functional schemata/: these are to be the
minimal models necessary to function over the set of related examples; the file
will indicate model sequences and correspondences with other models in the
file.
Models: Speculative, ascribed functional schemata/: these are to be the
minimal models necessary to function over the set of related examples; the file
will indicate model sequences and correspondences with other models in the
file.
Theories: Theories of model development: the possibilities this file
presents are: describing the minimal changes necessary to cover examples of
significant development; the possibility of holding in different states of
development alternate theories relating to the corpus; further, to the extent
that the models and theories can be made functional, it will be possible to
engage in regression testing of theory changes by applying them over the set of
models and examples.
Progress to date with the CASE project has been extensive but limited in kind. The original objective of this research was to explore the use of hypertext systems as a tool for advancing the analysis and modelling of detailed case studies. The conceptual focus was two-fold, on developing a database and psychological analyses, and on exploring the utility of hypertext for tasks involving the administration of complex bodies of information and even the development of and interconnection of functional models with them. Such remain the long term objectives of the research. In practice, to date the effort has focussed on establishing the overall structure into which the case material will be fit over time. Significant segments of the corpus of naturalistic observations have been entered into the online database. We have followed this procedure:
- information in the case corpus is brought on-line as ascii text files.
- those files and imported to the Notecards environment where they are broken up into small text records (stored on individual cards)
- an administrative structure is imposed on those records by storing them in hierarchically related systems of fileboxes.
- thematic structures are imposed on those records by relating records in the notecards to one another with links whose type varies across a spectrum of issues.
- the conclusion is a network of database of records which the analyist can navigate and modify as his questions and knowledge change.
A First Implementation
The current Dandylion database, developed at the Army Research Institute for the Behavioral and social Sciences (ARI) in the first six months of the project, occupies more than 3400 pages of the Xerox hard disk storage (this is approximately 1,700,000 characters). Figure 2 shows a top level view of that database. The central structure of the database derives from three indices, or main categories of data. Videotapes represents a catalog of the videotape corpus. Vignettes is a catalog of notes and short stories based on naturalistic observation. Citations is a reference list of the books that I have read or might read that I think should be relevant to analysis of the corpus.
Bushy Trees
The vignettes catalog in Figure 2 is a list of themes in the vignettes of naturalistic observations in the database. This text entered the database as an ascii file. The vignette database itself is a filebox of notecards, each of which contains text manipulable by a WYSIWYG editor. Each vignette card is created with text selected from the vignette catalog, cut, and pasted into a notecard. As needed, text of individual vignettes has been transcribed from the manuscript to a notecard and inserted in the vignettes filebox. The structure of the file is shallow and broad (720 notecards). The file is logically sequential, ordered by serial date from the day of the subject's birth. The sequence is explicit in the notecard labels through not in the physical organization of the database. For example, VN054 contains notes of motor development observed in the 54th day of the subjects life. Themes and issues that relate one vignette to another are represented by typed links threading the vignettes along a string of logical interconnection. The primary link types represent categories of infant development (motor, perceptual, cognitive, social) and study focal themes (language, physical objects, methodology). Since any protocol may contain information relevant to several themes, the threads interweave through the collection of protocols in a complex but comprehensible fashion.
Each sub-filebox in the videotape database of Figure 2 represents a single physical tape. Each videotape is divided into scenes (another subfilebox) named with a label of the form Tnnn.keyword, where nnn is the serial date in the subject's life and the keyword names either the other persons in the scene (a parent, sibling, or pet is typical) or the experimental materials used by the subject. Each scene is, as appropriate and as needed, further analyzed into thematically defined episodes which contain in turn sequences of actions, speech, and commentary by experimenters. For example, videotape "VT127.P018" in Figure 2 names a physical tape made on the 127th day of Peggy's life (in her eighteenth week).
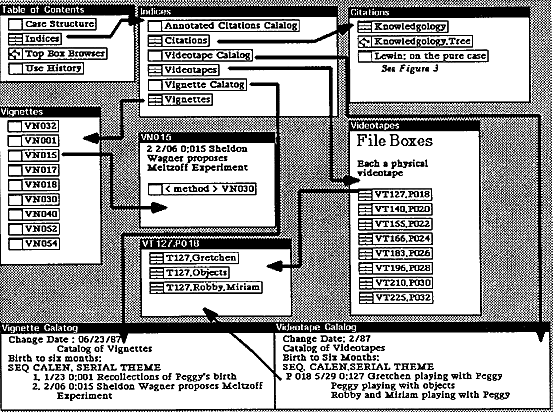
Overview of the Notecards CASE Files Structure
The subboxes "T127.Gretchen" and T127.Objects" specify scenes in which the subject was with her mother first and then with a specific collection of experimental objects. This database is also shallow and bushy, containing about 750 fileboxes representing scenes (each subdivided into episodes as well). The reason for this labelling is so that a simple lisp function can sort vignette and videptape card titles within a specific date range and order the material to support the correlation and interlacing of events noted in the naturalistic observation and recorded in the videotapes.
Progress and Limiations
The initial efforts in the first six months of this project were directed primarily towards familiarization with the system, database design, and the beginnings of database construction. Database construction took place in the Smart Technologies Group of the Army Research Institute for the Behavioral and Social Sciences, Washington, DC. The protocol material for the database was keyed online at a remote location as ascii files (now still available in this form), then mailed by arpanet to the laboratory at which they were integrated into the database by cutting and pasting text strings into notecards. At this point, I have available a structure with which I can begin the analysis and model building the corpus demands for its serious scientific exploration. Given that the database I'm constructing is very large and detailed, it should be no surprise that progress is slow, especially now that the effort has turned toward analysis of videotaped experiments. A beginning has been made in the analysis of videotape materials, but only at the top level of observation. The current phase may best be described as corpus adminstration. It is becoming clear that the effort will go forward in three waves which, although they will overlap, will follow this natural sequence. Corpus administration, corpus exploration, theory construction. The primary feedback loop ultimately will range between theory construction and corpus exploration, but before that can begin there must be a critical mass of material under review and at least partially online. Achieving that critical mass is the heart of the current effort. Since the psychological analysis needed to construct decent models of material in the Peggy corpus will take years, it should be no surprise that I have a need to work with other models now. During several years, I worked with Oliver Selfridge to develop simple models of interactive learning and implemented them in zetalisp on a Symbolics 3600. For a variety of reasons, I decided to convert those models to run in Object Logo on a Macintosh computer. I am now attempting to connect those models to their corpus in a project parallel to the CASE project effort.
The Psychology of the Particular
Many social scientists stand in awe of general theories. They typcially seek an abstract correspondence which will generally permit predictions that will cover many of the specific events that interest them. For me, the primary value of a general theory is more down to earth, more like what an engineer needs; it is the aid a theory offers in understanding and solving particular problems, such as what enabled a specific person to learn some particular knowledge in a given context. Why are case studies focussed on a single person worth paying attention to ? I believe these methods and objectives will help us approach a new way of doing psychology.
Kurt Lewin argued (1935) that psychology is now an Aristotelian science and will become a modern or Galilean science only when researchers shift their focus from finding cross classificatory correspondences to developing explicit explanations for series of events in concrete cases. In short, human psychology will become a science only when it begins solving problems in concrete cases, as one does in reading computer memory dumps or exploring machine learning. Lewin's specific proposals failed to engender such a transformation (see chapter 2 in Langer, 1967), yet there remains the sense that his attempt was profoundly right -- to move studies of mind from seeking correspondences to solving important problems in very specific and concrete cases.
The New Opportunity
If we can construct what Lewin refers to as "the pure case" (a corpus with a sufficiency of information to explain adequately all questions on which it might bear) and extend the modelling successes of function-oriented psychology, this should impact both theory formation and how one teaches psychology. The CASE project is one experiment in this spirit. We are trying to:
-
- capture a detailed body of information
- * development of alternative theories
- * application of our own theories to other cases/corpora.
- convert that corpus to an on-line database via variable depth transcription
- link related events and model development within the corpus
- offer that linked database and access to the corpus materials to the scrutiny and further development by colleagues in order to enhance:
Some may want to argue that such efforts are not scientific in the sense of permitting replicable experiments in other circumstances, but the effort is scientific in Peirce's broader sense -- an attempt to approach some imperfectly understood but well defined reality through seeking the convergence of opinion based on serious and extended inquiry. That is enough for me.
There is no magic in either cognitive modelling or the use of on-line tools for managing data, but their synergy will permit us to address and solve some long-standing, important problems in cognitive psychology. It is the problems which give the tools their importance. It is the new tools which give us some hope of coping with the problems by sharing our information, analyses, and ideas.
REFERENCES
K. Lewin. Aristotelian and and Galilean Modes of Thought in Contemporary Psychology. In A Dynamic Theory of Personality: Selected Papers of Kurt Lewin, McGraw Hill, 1935.
S. Langer. Idols of the Laboratory. Chapter 2 in Mind: An Essay on Human Feeling., (Vol.1). John Hopkins Press, 1967.
C. S. Peirce. The Fixation of Belief. In Chance, Love, and Logic (M. R. Cohen, ed.). Harcourt, Brace, and Co. 1923. Lessons from the History of Science. In Essays in the Philosophy of Science (Vincent Tomas, Ed.). Liberal Arts Press, 1957.
ACKNOWLEDGEMENTS
This work was undertaken through a senior research residency grant from the National Research Council at the Army Research Institute for the Behavioral and Social Sciences. My colleague, Joseph Psotka, director of the Smart Technologies Project at ARI ,was extraordinarily supportive and helpful. His suggestions have made this work much better than it could ever have been otherwise. Purdue has subsequently provided me a place and time to carry on this line of work.
Publication notes:
- Written in 1981. Unpublished.
- Published as an Information submissions to the First National Hypertext Conference, Chapel Hill, 1987.
- re-Published in this extended form in Hypertext: The State of the Art, McAleese and Green, Intellect, 1990.
Learning and Computing | Education | Computing | Psychology | Artificial Intelligence |